
Xiaomi e o companie cunoscută pentru telefoane, tablete, smartwatch și, mai nou, roboți. Compania a prezentat deja propriul robot umanoid în urmă cu ceva timp, are și mașini în portofoliu mai nou, iar acum producătorul își face loc în cercetarea avansată de robotică. Mai exact, a fost prezentat Xiaomi-Robotics-0, primul model de tip vision-language-action (VLA), open-source, cu 4,7 miliarde de parametri. Mai jos avem detalii!

E vorba despre un model capabil să vadă, să înțeleagă instrucțiuni în limbaj natural și să execute acțiuni fizice în timp real. Xiaomi susține că sistemul a obținut rezultate de top atât în simulări, cât și în teste din lumea reală, ceea ce îl plasează în competiție cu proiecte similare dezvoltate de laboratoare consacrate.
La nivel conceptual, un model VLA trebuie să rezolve un „circuit închis”. Vorbim despre percepție, decizie și execuție. Robotul vede mediul, interpretează ce i se cere, își face un plan și apoi îl pune în aplicare fără ezitări sau mișcări imprecise. Xiaomi spune că Robotics-0 a fost gândit tocmai pentru a păstra un echilibru între înțelegerea generală a contextului și controlul fin al mișcărilor. Aici apare și ambiția mai mare a companiei: ceea ce numește „inteligență fizică”, adică abilitatea unui sistem AI de a interacționa coerent cu obiecte reale, nu doar de a genera text sau imagini.

Din punct de vedere tehnic, modelul folosește o arhitectură Mixture-of-Transformers (MoT), care împarte responsabilitățile între două componente majore. Prima este un Visual Language Model (VLM), practic „creierul” sistemului. Acesta este antrenat să interpreteze instrucțiuni umane, inclusiv formulări ceva mai vagi. Componenta VLM se ocupă de detecția obiectelor, de întrebări și răspunsuri bazate pe imagine și de raționament logic. Cu alte cuvinte, este responsabilă pentru partea de înțelegere a mediului și a intenției utilizatorului.
A doua componentă este numită Action Expert și este construită pe un Diffusion Transformer (DiT) multistrat. În loc să genereze o singură acțiune izolată, sistemul produce ceea ce Xiaomi numește un „Action Chunk”, adică o secvență coerentă de mișcări. Abordarea cu secvențe de acțiuni este importantă în sarcini reale, unde manipularea unui obiect implică mai multe etape consecutive, nu doar un singur gest.
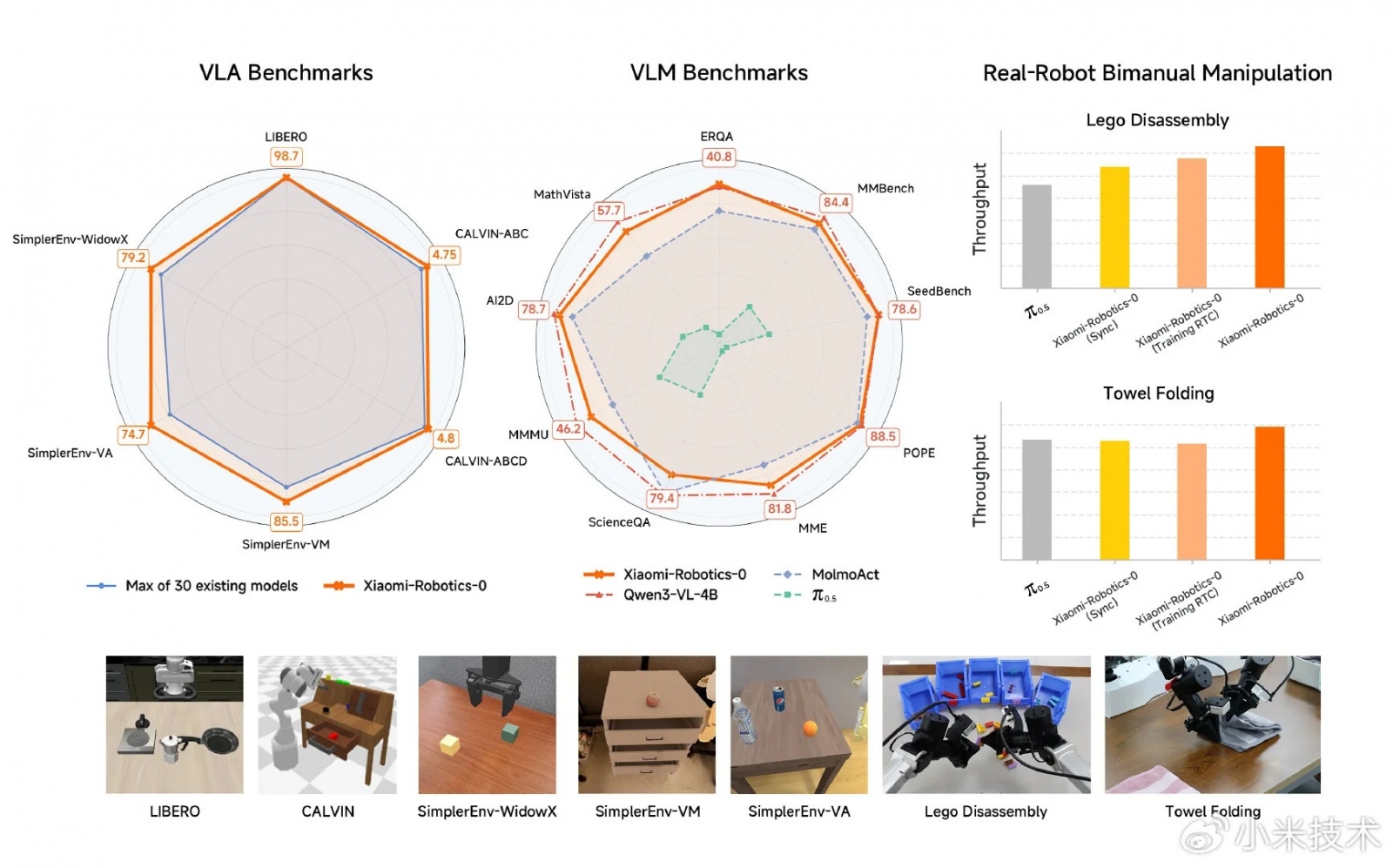
Un aspect sensibil la modelele VLA este compromisul dintre înțelegere și execuție. De multe ori, când un model este antrenat intensiv pe date de acțiune fizică, performanța sa pe partea de înțelegere multimodală scade. Xiaomi afirmă că a evitat această problemă prin co-antrenarea modelului pe date multimodale și pe date de acțiune, în paralel. În teorie, asta înseamnă că Robotics-0 poate continua să raționeze și să interpreteze corect mediul, chiar și după ce învață să manipuleze obiecte în mod precis.
Faptul că modelul este open-source îl face relevant și pentru comunitatea de cercetare, care poate testa, adapta și extinde arhitectura. Rămâne de văzut cum va fi integrat concret în produsele Xiaomi sau în parteneriatele industriale. Pare totuși că Xiaomi nu vrea să fie doar un jucător în zona de hardware de consum, ci un nume activ în dezvoltarea inteligenței artificiale, aplicate în robotică.










