Imaginaţi-vă momentul acela când sunteti la un restaurant cu 10 prieteni şi toţi vorbiţi unul peste altul şi iese babilonie. Ei bine, Google reuşeşte să rezolve această problemă, dar nu într-un mod benevol, ci printr-o tehnologie ce duce cu gândul la Big Brother. Recunoaşterea vocală funcţiona excelent şi până acum, dar nu era capabilă să distingă vocile din mulţime.
Aveţi mai jos un clip care prezintă noua tehnologie de la Google, care pe baza unui AI izolează sursa sunetului separat în cazul fiecărui vorbitor. Separarea unui feed audio de sunetele ambientale sau chiar de alte voci este un aspect la care mintea umană e bună, dar sistemele automate aveau probleme cu aşa ceva până acum. Noi putem să ne axăm pe un singur vorbitor într-o cameră plină de oameni, dar un computer şi un sistem de microfoane nu putea... de obicei.
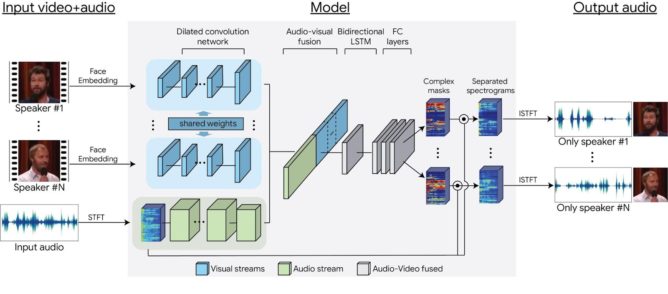
Cei de la Google au creat un sistem pe bază de machine learning care poate alege anumite sunete precum vorbitul dintr-un clip video. A fost capabil să separe complet discursul unui stand up comedian de cel al altuia care vorbea la volum maxim lângă el. Cercetătorii au "antrenat" AI-ul propunându-i "petreceri false", adică mulţi oameni vorbind unul peste altul, dar sub formă a multiple sample-uri tăiate manual şi suprapuse.
Aşa a învăţat sistemul să discearnă între ele. Datele ajung apoi într-o reţea, care analizează şi mişcările faciale din video şi spectrogramele track-ului audio. Rezultatul? Se stabilesc care frecvențe şi în care momente corespund unui anumit vorbitor, iar apoi datele sunt extrase pe un track audio izolat.
Mă gândesc din start la o utilizare pentru sistem: la talk showurile politice unde toată lumea se suprapune. Sau pentru a identifica un terorist care tocmai a comis o faptă şi vrea să scape în mulţime, vorbind la telefon cu acoliţii.